Auto Invoice

Automating invoice creation
This entry is about my application of programming to automate an important albeit time-consuming project management task: creating invoices.
Problem Statement
At the end of each month I will need to create invoices for 20+ projects. Granularity of the invoice is broken down at ticket, category, and project levels. This is how this task was being done. Data were exported from a time tracking app to Google Sheets where pivot table was used to aggregate the numbers. Next, I would have to type each ticket number in an invoice card, and copy and paste the hours and fee accordingly. It has been time-consuming, and not to mention it is inductive to human errors during the copy and paste exercise.
In the beginning, automating this task was almost impossible because category was not standardized across projects, and there were too many data entry errors or missing data. It took a month or two to implement and enforce good data entry practices among our team as well as standardize the categories across all projects. It was the first crucial step that makes this automation possible.
Given the multi-hierarchy aggregation requirement, it is too cumbersome to use Pandas even though the groupby function in Pandas does support multi-hierarchy aggregation to some extent. Instead, I’ve utilized Python to aggregate the hours and cost at ticket, category and project levels.
Understanding the Data
The screenshot below is a snapshot of the data input. In this data sample there are seven columns and 232 rows. Each row is one time entry that records the hours and billable amount for a particular task done for a particular ticket that belongs to a particular project during a period of time. For instance, the first entry records 1.25 hours spent on doing quality assurance testing for ticket 52050 of project Neeko on 2023-11-29, and this entry can be billed for $218.75. One ticket can have several entries (rows).
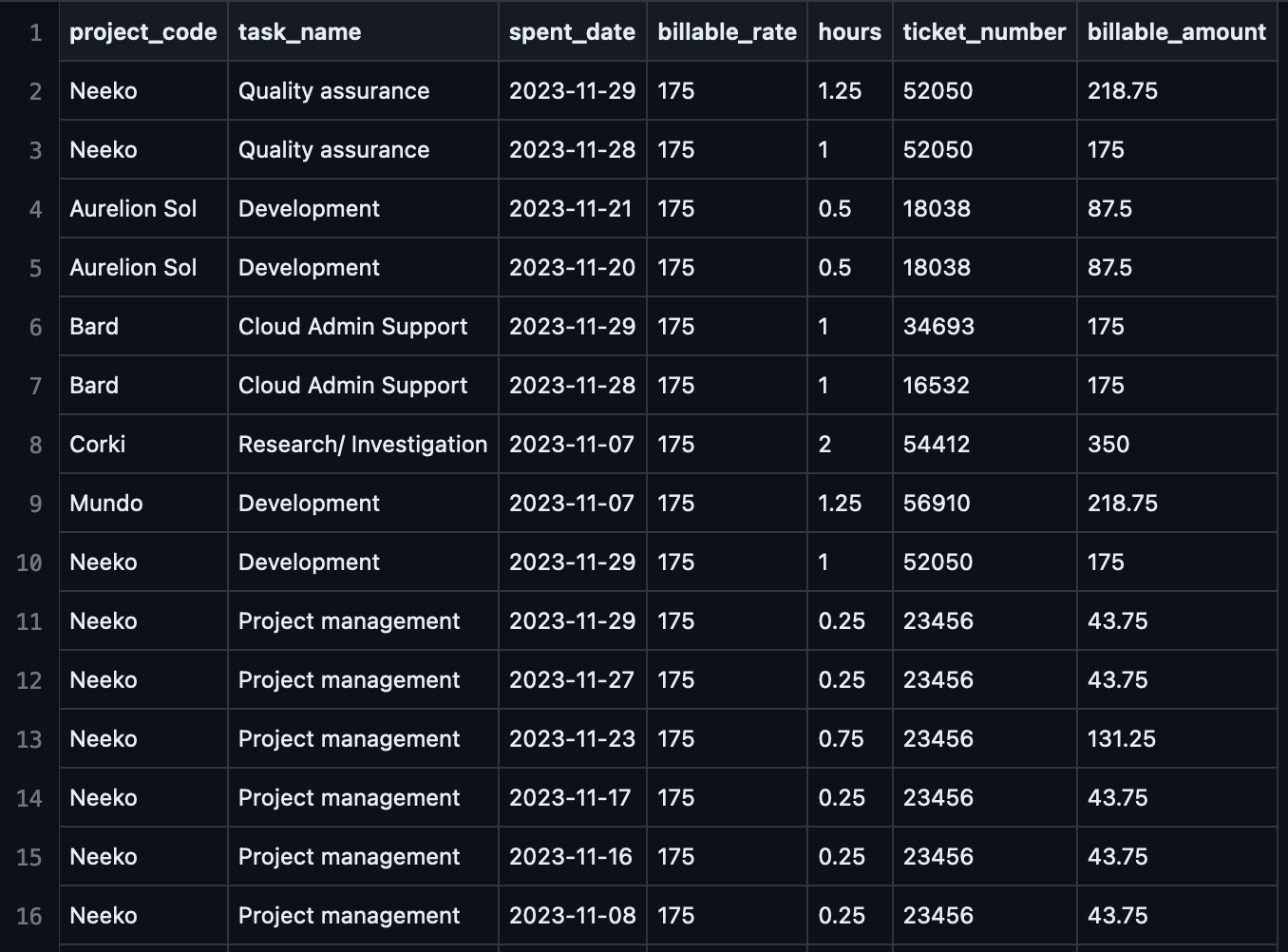
Task_name column is indeed the task category with the following values: Development, Quality assurance, Cloud Admin Support, Research/ Investigation, Design, Project management, Client meetings. This classification is helpful for internal review of team utilization but can be a little too much for our clients. Therefore some modifications are needed. Specifically,
The time spent on Development and Quality assurance per ticket is put together, and goes under the category of Development.
Project management and Client meetings don’t need breaking down to ticket level.
Below is the invoice sample output. It shows how an invoice for one project should look like.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
✅ Invoice sample
Teemo
Client meetings: 8.25 hours - $1,443.75
Cloud Admin Support:
- Ticket 75925: 4.0 hours - $700.0
- Ticket 77706: 2.0 hours - $350.0
- Ticket 95361: 1.5 hours - $262.5
Project management: 6.25 hours - $1,093.75
Research/ Investigation:
Ticket 18009: 2.75 hours - $481.25
- Ticket 75925: 8.0 hours - $1,400.0
- Ticket 71593: 0.5 hours - $87.5
- Ticket 77706: 1.0 hours - $175.0
Development:
- Ticket 75925: 9.5 hours - $1,662.5
- Ticket 71593: 0.5 hours - $87.5
Total: 44.25 hours - $7,743.75
Code Explanation
The codebase and data sample can be found here.
The code follows a step-by-step approach, starting with reading the data, cleaning it, and then processing and aggregating the information at different levels (ticket, category, project).
The code is organized into functions, each serving a specific purpose. This modular design makes the code easier to understand and maintain. Each function has a clear responsibility, such as grouping data, aggregating totals, or formatting strings.
Data Reading and Cleaning
Reading the data from a CSV file into a Pandas DataFrame, followed by a data cleaning process where a new column (cat_name) is created based on the values of an existing column (task_name). The code ensures that the ‘Quality assurance’ value is replaced with ‘Development’ in the ‘cat_name’ column.
1
2
3
data = pd.read_csv(filename, usecols=['project_code', 'ticket_number', 'task_name', 'hours', 'billable_amount'])
data['cat_name'] = data['task_name']
data['cat_name'].replace('Quality assurance', 'Development', inplace=True)
Data Conversion
After data cleaning, the DataFrame is converted into a list of dictionaries. Each row in the DataFrame becomes a dictionary, making it easier to work with and allowing for a more versatile data structure.
1
data = data.to_dict('records')
Grouping and Aggregation
Define a series of functions (group_by_key, aggregate_ticket_totals, aggregate_cat_totals, aggregate_project_total) to group and aggregate data at different levels—ticket, category, and project.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
def group_by_key(items, key):
"Group a list of dictionaries by a key"
result = {}
for item in items:
value = item.get(key, None)
if value not in result:
result [value] = []
result [value].append(item)
return result
def aggregate_ticket_totals (entries):
"Aggregate hours and fee by ticket"
tickets = []
for key, value in group_by_key (entries, 'ticket_number').items():
ticket = {}
ticket ['ticket_number'] = key
ticket ['ticket_entries'] = value
ticket_total = {'total_hours': 0, 'total_$': 0}
ticket ['ticket_total'] = ticket_total
for entry in value:
ticket_total ['total_hours'] += entry ['hours']
ticket_total ["total_$"] += entry ['billable_amount']
tickets.append (ticket)
return tickets
def aggregate_cat_totals (entries):
"Aggregate hours and fee by category"
cat = {}
cat ['cat_name'] = entries ['cat_name']
cat ['tickets'] = entries ['tickets']
cat_total = {'total_hours': 0, 'total_$': 0}
for ticket in entries ['tickets']:
cat_total ['total_hours'] += ticket ['ticket_total']['total_hours']
cat_total ['total_$'] += ticket ['ticket_total']['total_$']
cat ['cat_total'] = cat_total
return cat
def aggregate_project_total (entries):
"Aggregate hours and fee by project"
project_level_output = {}
project_level_output ['project_code'] = entries ['project_code']
project_level_output ['cats'] = entries ['cats']
project_total = {'total_hours': 0, 'total_$': 0}
project_level_output ['project_total'] = project_total
for cat in entries ["cats"]:
project_total ['total_hours'] += cat ['cat_total']['total_hours']
project_total ['total_$'] += cat ['cat_total']['total_$']
return project_level_output
Stringification
The next set of functions (stringify_ticket_totals, convert_list_to_str, stringify_cat_totals, stringify_cat_header, stringify_project_totals) are responsible for converting the aggregated data into formatted strings.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def create_invoices (data):
"Create invoices"
results = ''
for project, project_entries in group_by_key (data, 'project_code').items():
# create an input dictionary with keys=['project_code', 'cats']
entries_per_project = {}
entries_per_project ['project_code'] = project
cats = []
entries_per_project ['cats'] = cats
for cat, cat_entries in group_by_key (project_entries, 'cat_name').items():
ticket_input = {}
ticket_input ['cat_name'] = cat
tickets = aggregate_ticket_totals (cat_entries)
ticket_input ['tickets'] = tickets
cat_total = aggregate_cat_totals (ticket_input)
cats.append (cat_total)
project_total = aggregate_project_total (entries_per_project)
result = stringify_project_totals (project_total)
results += result + '\n\n'
return results
Invoice Generation
The create_invoices function acts as the orchestrator, calling the grouping, aggregation, and stringification functions. It iterates through projects, categories, and tickets, aggregates totals, and formats the data into a coherent invoice report.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def create_invoices (data):
"Create invoices"
results = ''
for project, project_entries in group_by_key (data, 'project_code').items():
# create an input dictionary with keys=['project_code', 'cats']
entries_per_project = {}
entries_per_project ['project_code'] = project
cats = []
entries_per_project ['cats'] = cats
for cat, cat_entries in group_by_key (project_entries, 'cat_name').items():
ticket_input = {}
ticket_input ['cat_name'] = cat
tickets = aggregate_ticket_totals (cat_entries)
ticket_input ['tickets'] = tickets
cat_total = aggregate_cat_totals (ticket_input)
cats.append (cat_total)
project_total = aggregate_project_total (entries_per_project)
result = stringify_project_totals (project_total)
results += result + '\n\n'
return results
Write to File
The last step is to write the invoices into a text file, ready to be sent!
1
2
with open("invoices.txt", 'w') as f:
f.write(create_invoices(data))
Impact
This automation is a huge help. I’ve been able to cut down the time spent on creating invoices from a few hours to less than half an hour (I know!), and minimize the errors during copy and paste.